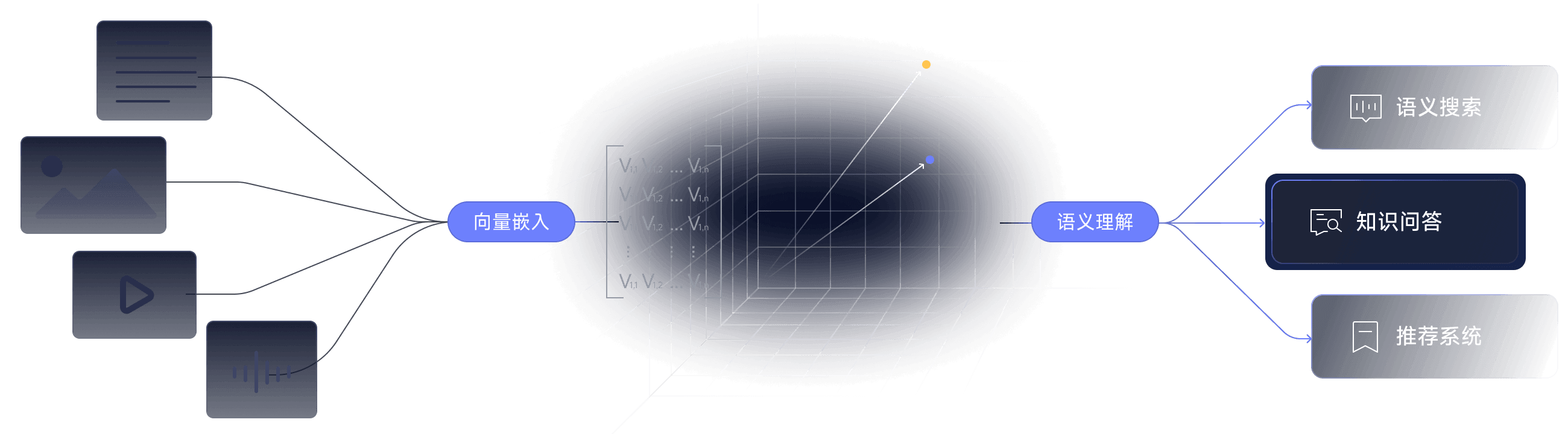
从原始数据到智能检索,全链路覆盖
原始数据准备
对原始文档、网页、知识库等数据进行智能清洗、分段(Chunking)、格式化和脱敏处理,为后续向量化奠定高质量基础。
向量化嵌入
调用高精度向量模型,将处理后的数据块转化为语义丰富的向量嵌入,从而实现从文本到机器可理解的数学表示。
向量索引构建
将生成的向量嵌入存储到高精度向量数据库,完成大规模索引构建,支持亿级规模数据的快速存储、高效索引与无缝管理。
智能混合检索
结合向量相似性搜索与关键词检索 ,并通过重排序技术精选高相关性结果,大幅提升召回准确率。
RAG 应用集成
注入检索到的优质上下文,实现准确、可解释的智能问答,无缝对接 LangChain、LlamaIndex 等主流框架。
向量化赋能,解决AI落地核心难题
业务痛点&向量化如何解决
知识陈旧,无法回答实时问题
大模型知识截止到训练日期,无法获取实时业务数据,导致回答滞后、信息过时。
实时动态知识接入
通过向量检索实时连接企业新增知识库,让模型随时获取实时信息,保持答案时效性。
模型幻觉频发,答案缺乏依据
大模型容易编造内容,难以追溯真实出处,结果不可信、不可用。
RAG 真实依据生成
基于检索到的真实资料生成答案,结果可追溯、可解释,大幅降低幻觉风险。
企业内部数据无法被模型利用
文档、数据库、报表等非结构化数据长期处于孤岛状态,无法被模型理解与调用。
语义知识库构建
将非结构化数据向量化,转化为模型可理解的语义知识库,彻底打破数据孤岛。
传统关键词搜索体验差
匹配率低、召回不准,用户找不到想要的内容,体验不佳、转化受限。
语义向量搜索
理解用户真实意图,即使关键词部分匹配也能高效召回,大幅提升搜索相关性和用户体验。
Dataify 核心优势
私有部署,安全可控
支持在企业自有的私有云或本地环境部署,敏感数据无需出域即可获得完整的向量检索能力,满足金融、医疗、政务等高合规行业的数据安全要求。
轻量集成,分钟接入
提供简洁易用的API接口,仅需几行代码即可将向量检索能力接入现有系统。无需重构搜索架构,无需复杂配置,快速验证语义搜索与RAG应用效果。
多语言支持,20+语种
内置多语言向量模型,支持中、英、日、韩、法、德等20+常用商务语言。无论是跨国业务还是本地内容,均能实现精准的跨语言语义检索。
混合检索,召回更准
融合向量检索与关键词检索(BM25)双路召回,结合轻量级重排序优化结果。在保证高召回率的同时,显著提升搜索结果的相关性与准确性。
成本可控,按需扩展
提供灵活的计费方式与轻量化部署方案,支持从小规模试点到生产级应用的平滑扩展。无需为未使用的算力付费,有效控制项目起步成本。
全天候技术支持,快速响应
提供全天候技术支持,专业工程师团队随时待命,快速响应部署集成、性能优化、运维等各类问题,确保业务连续性,让您的AI应用始终稳定运行。
向量模型应用场景

大模型知识库(RAG)
将企业内部文档、产品手册、FAQ等构建成知识库,让大模型基于真实、可追溯的资料生成答案,降低幻觉风险,确保回答合规可靠。
语义搜索
深入理解用户真实意图,即使关键词部分匹配,也能高效召回相关内容,大幅提升搜索体验、结果相关性与业务转化率。
多模态检索
支持以图搜图、图文互搜、视频片段检索等跨模态能力,广泛应用于电商商品搜索、设计素材匹配、版权保护与内容发现等场景。

智能推荐
基于用户行为、物品内容与上下文的向量相似性,实现个性化商品/内容推荐、相似项推荐,提升点击率、转化率与用户留存率。

内容审核与去重
通过向量相似度快速检测重复内容、相似侵权素材或潜在敏感信息,显著降低人工审核成本,提高平台内容治理效率。

智能客服与问答
对用户咨询进行深层语义理解,高效识别用户意图,从知识库中快速匹配相关答案,提升自助服务效率、初次解决率与用户满意度。
构建企业级向量检索,提升AI性能
私有部署 · 混合检索 · 多语言支持 · 分钟级接入