一、 从数据孤岛到结构化数据资产
在当今由人工智能(AI)和大语言模型(LLM)驱动的时代,数据已成为驱动技术进步的核心要素。数据的质量,而非单纯的数量,直接决定了算法模型性能的上限。高质量的数据能够为模型提供更准确、更丰富的学习信号,显著提升其预测、泛化与鲁棒性;反之,低质量数据引入的噪声与偏差,往往会导致先进算法失效。
数据处理正经历从早期 ETL (提取、转变、加载) 到 数据湖仓一体化 (Data Lakehouse) 架构的深刻变革。这种新范式旨在实现海量多源异构数据的统一存储与实时分析。以Dataify 为代表的工业级数据集产品,正是通过将 Amazon、LinkedIn 等平台的原始数据转化为结构化资产,解决了从原始数据形态到可直接调用资产的全生命周期管理问题,确保持续的内在价值。
二、 原始数据采集与接入管理 (Data Ingestion & Connectivity)
数据采集的稳定性与效率是后续环节的基石。在面对海量、碎片化的数据源时,构建高可用、高并发的系统至关重要。
协议层优化
为了确保采集的稳定性,需要对底层网络协议进行深度优化。这包括连接池管理、超时重试机制、流量管理及错误处理。Dataify 通过精细化管理网络策略,有效应对网络波动与目标服务过载,确保数据流的持续性。在大规模分布式场景中,利用并发优化和高可用架构(High Availability)防止数据丢失或重复。
反数据采集技术
在公开数据获取过程中,处理反数据采集机制是核心技术挑战:
•TLS 指纹模拟 (TLS Fingerprinting Simulation):现代系统通过分析 TLS 握手特征(如 JA3、JA4 指纹)识别自动化请求。Dataify 深入研究 JA4 等先进识别机制,通过精确模拟主流浏览器的加密套件与扩展字段,使采集流量在协议层更接近真实用户行为,有效规避服务端扫描与不允许访问。
•动态频率调节(Dynamic Frequency Control):通过部署全球分布式节点并结合智能调度,系统可模拟真实用户分散、随机的访问模式。根据目标站点的响应速度与动态调整频率,降低了触发异常检测的概率。
流式与批处理结合
Dataify 采用流批一体架构。针对时效性要求高的场景(如 LinkedIn 动态数据),利用 Apache Flink 实现毫秒级延迟的流式处理;针对历史归档(如 Zillow 房产历史),则采用高效的批处理模式,确保时效性与吞吐量的平衡。
- 流式处理 (Stream Processing):利用 Flink 或 Spark Streaming 实时捕获数据,实现毫秒级延迟,适用于实时更新的社交动态数据。
- 批处理 (Batch Processing):适用于历史数据归档或周期性报告,如房产交易历史等。采用流批一体架构,可根据不同业务需求在时效性与吞吐量之间取得动态平衡。
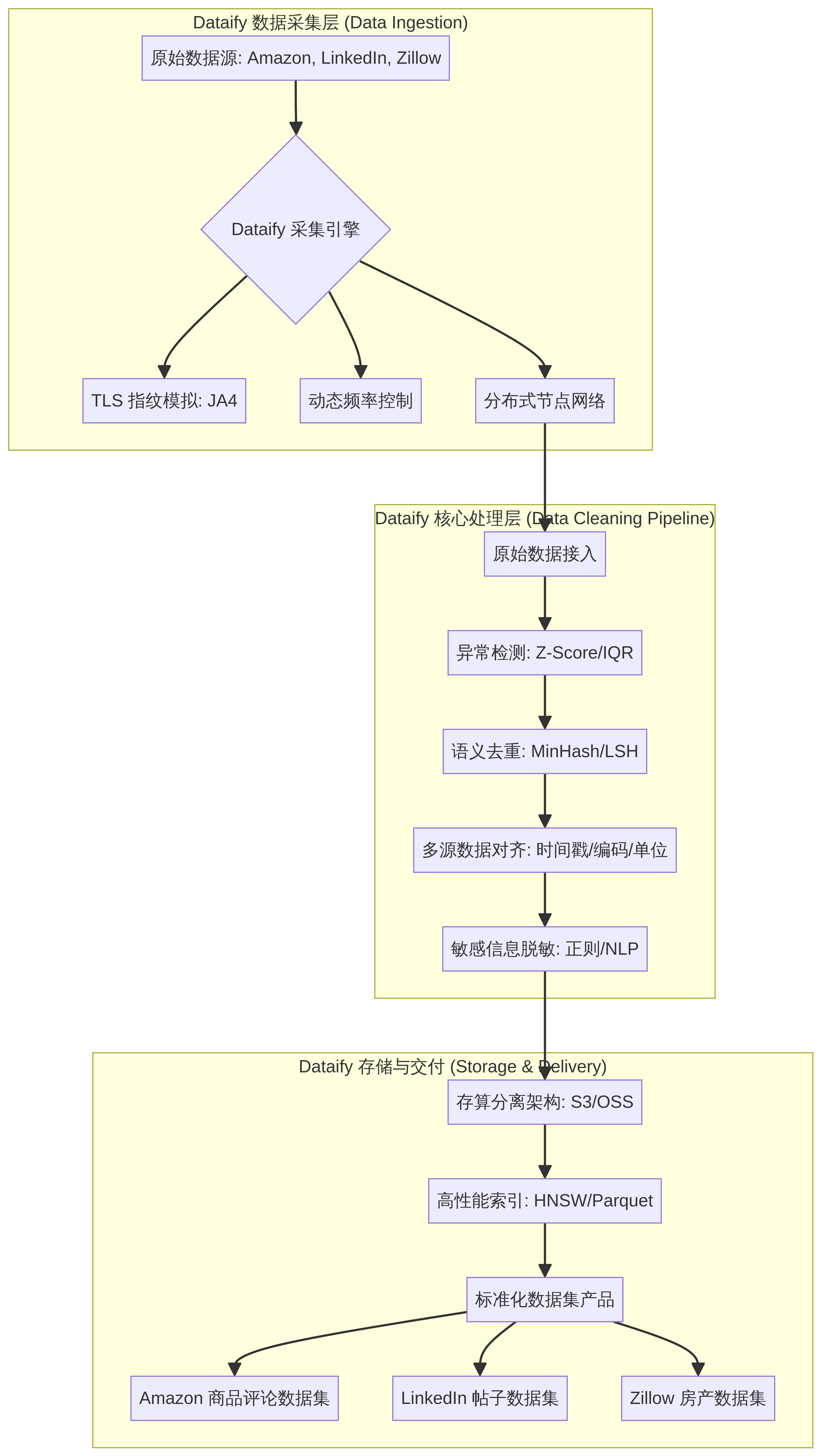
三、 核心处理流程:工业级数据清洗 (Data Cleaning Pipeline)
原始数据往往包含大量不能直接拿来使用的内容,若直接用于模型训练将严重影响其性能。因此,工业级的数据清洗是构建高质量数据集不可或缺的环节。Dataify数据集在此阶段投入了大量研发,通过一系列精细化处理,将从海量网络中采集的原始数据转化为干净、一致、可用的结构化资产,为下游应用提供坚实基础。

异常检测与过滤
异常数据(Outliers)可能由传感器故障、数据录入错误或大量攻击等原因造成,它们会扭曲数据分布,误导模型学习。Dataify 采用多层异常检测机制,确保数据纯净度:
•统计学方法:过滤评分偏差过大或长度异常的文本,剔除掉无意义的内容。
•语义重复度检测 (Semantic Duplication Detection):针对大规模文本,传统哈希无法识别近重复内容。
多源数据对齐
当数据来源于不同系统或平台时,常常面临格式不统一、时间戳不一致等问题,这需要进行精细化的对齐操作。Dataify 针对其多源数据集产品(如 Amazon 商品数据集 可能包含来自不同区域站点的数据)建立了严格的对齐标准:
•时间戳偏移校正:统一转变为 UTC 标准时区及 UTF-8 编码,消除乱码及跨时区解析错误。
•编码格式统一:数据可能以 UTF-8、GBK、ISO-8859-1 等不同编码存储。
•单位不统一问题:如将 Zillow 房产数据 中的面积(平方英尺/平方米)及货币统一,确保跨区域数据的可比性。
敏感信息脱敏与合规内控
Dataify 将合规性视为产品的生命线。在处理 Amazon 或 LinkedIn 等包含 PII(个人身份信息)的数据源时,系统内置了符合道德标准的自动化合规引擎:
- 自动化脱敏 (De-identification):利用 NLP 模型(NER)实时识别非结构化文本中的姓名、地址等信息。
- 差分隐私 (Differential Privacy):在交付大规模统计数据集时,通过引入可控噪声,确保个体隐私无法被逆向推导,同时保持全局统计特征的真实性。
- 可审计的数据血缘:每一份交付的数据集均附带合规溯源报告,明确标注数据处理的每一步逻辑,满足企业级安全合规评估需求。
四、 进阶特征工程与增强 (Feature Engineering & Augmentation)
特征工程是机器学习和深度学习模型成功的关键环节,它将原始数据转化为模型能够理解和学习的有效特征。而数据增强则通过扩充数据集,提升模型的泛化能力和鲁棒性。
结构化转变
许多有价值的信息以非结构化形式存在,如网页(HTML)、文档(PDF)或图片。将其转化为结构化数据是特征工程的重要一步。Dataify 在处理其多样化的数据集产品时,尤其擅长此项工作:
•非结构化数据(如 HTML/PDF)的语义提取技术:Dataify 利用先进的自然语言处理(NLP)技术和计算机视觉技术,从非结构化数据中识别并提取关键信息。例如,在构建 Amazon 商品数据集 时,我们不仅采集商品标题、描述,还会从商品详情页的 HTML 结构中提取规格参数、品牌信息、销售排名等。对于 Zillow 房产数据集,则会从房源描述文本中提取房屋特色、周边设施等语义信息,并将其结构化为可分析的字段。
•向量化处理(Embedding):将非数值型数据转化为高维数值向量。Dataify 针对其数据集产品,如 Amazon 商品评论数据集,会利用 BERT 等预训练语言模型将评论文本转化为语义丰富的向量。对于 LinkedIn 帖子数据集,除了文本内容,我们还会对图片、视频等媒体内容进行特征提取和向量化,为后续的推荐系统提供强大的输入。
数据增强(Data Augmentation)
数据增强旨在通过生成新的训练样本来扩充数据集,尤其在原始数据量不足时,可以有效缓解过拟合,提升模型性能。Dataify 在为客户提供定制化数据集时,也会根据需求应用数据增强技术:
•针对小样本数据的合成技术(如 SMOTE):针对 Amazon 商品评论数据集 中罕见的负面评论类型,Dataify 采用 SMOTE 算法,通过在少数类样本之间插值生成新的合成样本,平衡数据集,优化模型对这些关键少数类别的识别能力。
•利用生成式 AI 构造样本,提升模型的鲁棒性:Dataify 探索利用生成网络(GANs)等生成式 AI 技术。通过生成具有特定扰动的新样本,训练模型更好地应对各种输入变化,提升其在面对噪声、攻击或未见过数据时的鲁棒性。
五、 存储架构与索引优化 (Storage & Indexing)
高效的数据存储和检索是支撑大规模数据处理的基础。Dataify 数据集 在其后端架构中,充分利用了先进技术确保标准化数据集(如 Amazon 商品评论数据集、LinkedIn 帖子数据集、Zillow 房产数据集 等)的高效存储与快速交付。
存算分离架构
Dataify 采纳了 存算分离 (Storage-Compute Separation) 核心思想,将数据存储在 Amazon S3 或 OSS 等对象存储中,计算任务在独立集群上执行。其优势在于:
•弹性伸缩:存储和计算资源可以根据实际需求独立进行弹性伸缩,减少资源浪费。
•成本优化:对象存储通常比块存储或文件存储更经济,且按需付费模式进一步降低了成本。
•高可用性与持久性:对象存储服务通常提供高冗余和高持久性,确保数据安全。
•多租户与共享数据:不同的计算引擎可以共享同一份存储数据,减少数据冗余和数据一致性问题。
高性能索引
为了从海量数据中快速检索所需信息,高性能索引技术至关重要,尤其是在向量搜索和结构化数据查询场景。Dataify 针对其多样化的数据集产品,构建了优化的索引系统:
•针对向量数据的相似度检索(HNSW 算法):在处理文本或多模态 Embedding 时,Dataify 广泛应用 近似搜索。HNSW 算法是其核心,通过构建多层图结构显著降低查询延迟,使用户可以快速进行语义相似性搜索。
•针对结构化数据的列式存储(Parquet/Avro)优化方案:对于大规模结构化数据(如 Amazon 商品属性、Zillow 房屋特征),采用 列式存储 (Columnar Storage) 格式如 Apache Parquet 和 Apache Avro,大幅减少 I/O 开销并提升查询效率。这些格式与 Spark、Hive 等框架紧密集成,是Dataify 构建数据湖和数据仓库的基石。
六、 自动化链路与质量监测 (DataOps)
Dataify 数据集 将 DataOps 实践融入整个生命周期管理,确保 亚马逊商品数据集、Amazon 商品评论数据集、LinkedIn 帖子及公司数据集、Zillow 房产数据集 等产品始终保持高水准。
CI/CD 在数据中的应用
Dataify 将程序工程中的 CI/CD (持续集成/持续部署) 实践引入数据领域,实现了数据处理工作流的自动化构建、测试和部署:
•工作流编排:利用 Apache Airflow 或 Prefect 定义自动化工作流。例如针对 Amazon 商品评论数据集 的每日更新,自动化管道定时触发采集、清洗、脱敏、向量化等任务。
•版本选择与测试:代码、配置和数据模型纳入 Git 版本选择。每次提交后自动触发单元测试、集成测试和数据质量测试(如 Schema 验证、范围检查),确保产出的正确性。
质量基准测试
持续的数据质量监测是 DataOps 的核心组成部分。Dataify 通过建立全面的质量基准和实时监控机制,能够及时发现并解决数据问题,从而保证其数据集产品的卓越品质:
•数据健康度仪表盘:实时展示关键数据指标(缺失值比例、异常值数量、数据分布等),帮助工程师一目了然地了解其数据集产品的“健康状况”。
•数据分布漂移(Data Drift):通过计算统计距离(如 KL 散度)监控新旧数据变化。一旦 Amazon 商品评论数据集 等数据分布发生显著漂移,系统立即告警并启动回溯或重训练流程,确保模型持续有效。
七、 构建可持续的数据生态
在数据驱动的时代,高质量数据集是取得竞争优势的关键。数据即代码正在成为现代数据治理的核心。Dataify秉持这一理念,将拥有的数据集产品的生产流程标准化、自动化,并进行严格的版本筛选和质量检测。通过将数据视为可编程、可演进的资产,实现了处理流程的可复现性,大幅提升了其 亚马逊商品数据集、Amazon 商品评论数据集、LinkedIn 帖子数据集、LinkedIn 公司数据集、Zillow 房产数据集 等产品的价值和利用效率。
展望未来,数据处理将向智能化、实时化和自治化发展。Dataify数据集将持续投入研发,优化数据采集、清洗、特征工程和存储索引技术,赋能业务创新与增长,助力客户在 AI 时代取得成功。